Spring 에서 Master Slave Datasource 분리하기
개요
데이터베이스에서 고가용성을 위한 작업으로 Replication 을 선택하는 것은 거의 당연한일이다.
이외에도 Replication 을 가지면 얻을 수 있는 특징은 아래와 같다.
- High Availability
- Scalability
- DisasterRecovery
- Backup
- Analysis
- DataWareHouse
Application 의 요청을 처리하는 DB 인스턴스가 하나일 경우
모든 쓰기 요청과 읽기 요청 대해서 작업을 처리해야하는 문제가 발생한다.
당연스럽게도 대용량의 요청이 들어오면 이를 처리하지 못해 지연 및 장애가 발생하게 된다.
(Scale Up 으로 해결할 수 있으나, 더 많은 대용량 요청이 들어오면 한계가 드러난다.)

사실 단일 DB 인스턴스 뿐만 아니라 분산 환경에서도 문제가 발생할 수 있다.
여러 서버 그리고 여러 DB 가 다대다 관계로 존재한다고 가정한다.
모든 쓰기 요청과 읽기 요청이 중첩되서 호출될 것이고 진입점
즉, 호출하는 서버가 하나 더 늘어나게 되면, 더 큰 부하를 야기하게 될 것이다.
이 같은 문제를 Replication 과 CQRS 그리고 Query Offloading 을 통해 해결할 수 있다.
CQRS(Command and Query Responsibility Segregation)는 명령 및 쿼리 책임 분리로
쓰기와 읽기를 분리하는 것으로 실제 우리가 수행하는 작업에 따라 바라보는 대상을 달리하는 것이고
Query Offloading 은 읽기 분배라는 뜻으로 읽기 수행에 있어서 여러 노드로 분산을 한다는 뜻이다.
정리하자면 아래와 같다.
- Master에게는 데이터 동시성이 높게 요구되는 트랜잭션을 담당한다.
- Slave에게는 데이터 동시성이 꼭 보장될 필요는 없는 읽기 전용 트랜잭션을 담당한다.(분산 가능)
CQRS 를 애플리케이션 구현 패턴(읽기/쓰기 서비스 분리)로 볼 수 있겠지만
여기서는 개념만 따왔다는 점만 양해 부탁드리고
그리고 꼭 위 같은 방법으로만 해결할 수 있는 것은 아니라는 것도 유념 바란다.(cluster, sharding 등등)
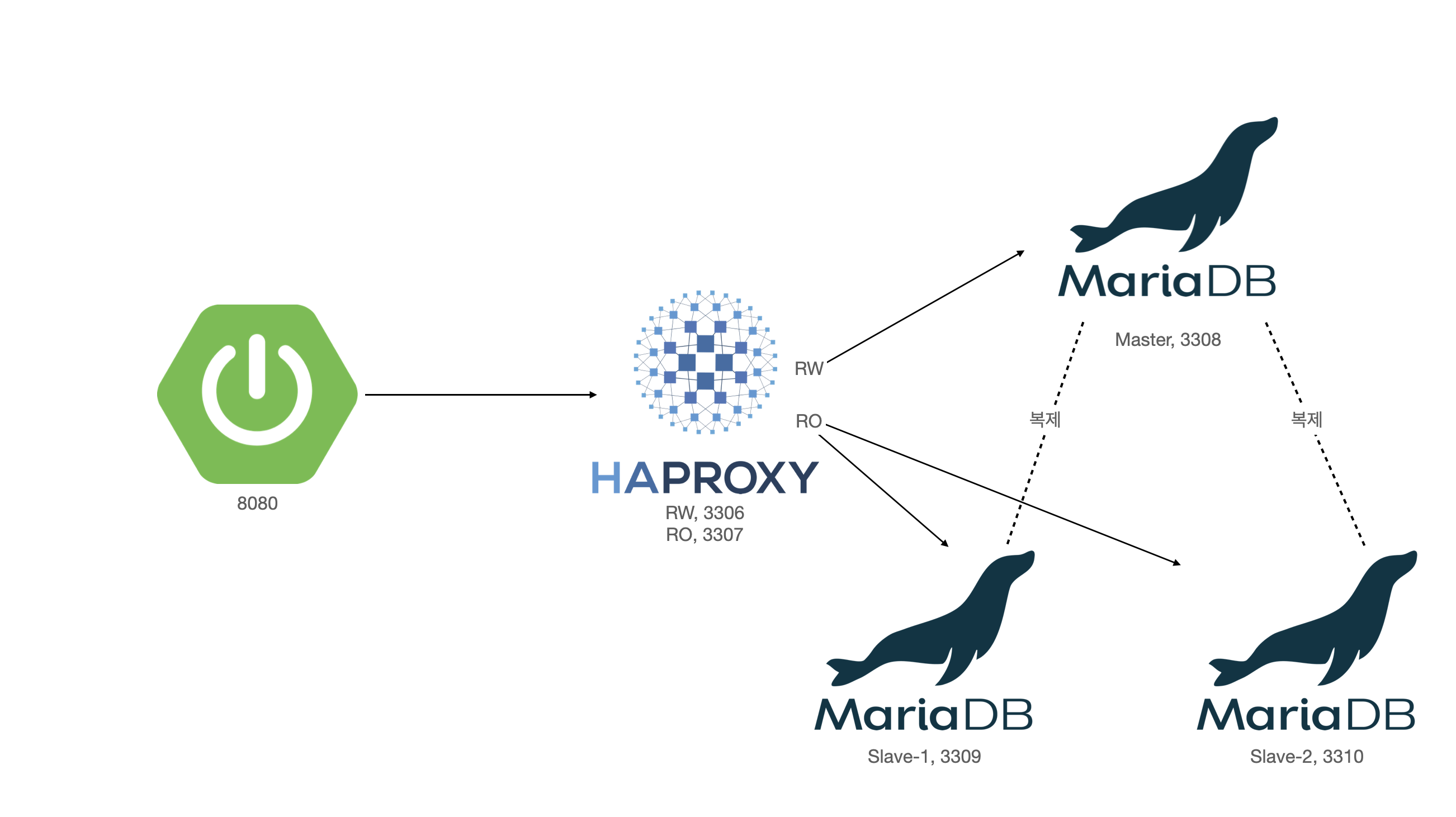
시스템 아키텍처
예제 프로젝트를 구성하는 스킬셋은 아래와 같다.
- Spring Boot, MVC, JPA
- MariaDB & Replication, HAProxy
- Docker, Docker-Compose
예제 아키텍처는 다음과 같다.
전체 소스 코드는 다음 링크에서 확인이 가능하다.
GitHub - the-developer-lab/the-server-lab: the-server-lab
the-server-lab. Contribute to the-developer-lab/the-server-lab development by creating an account on GitHub.
github.com
GitHub - the-developer-lab/the-server-lab: the-server-lab
the-server-lab. Contribute to the-developer-lab/the-server-lab development by creating an account on GitHub.
github.com
구현하기
DataSource 란?
JDBC DriverManager, HikariCP, DBCP 와 같은 구현체의 추상화로
Java 에서 다양한 라이브러리로부터 Database 커넥션을 활용할 수 있도록 만든 인터페이스.
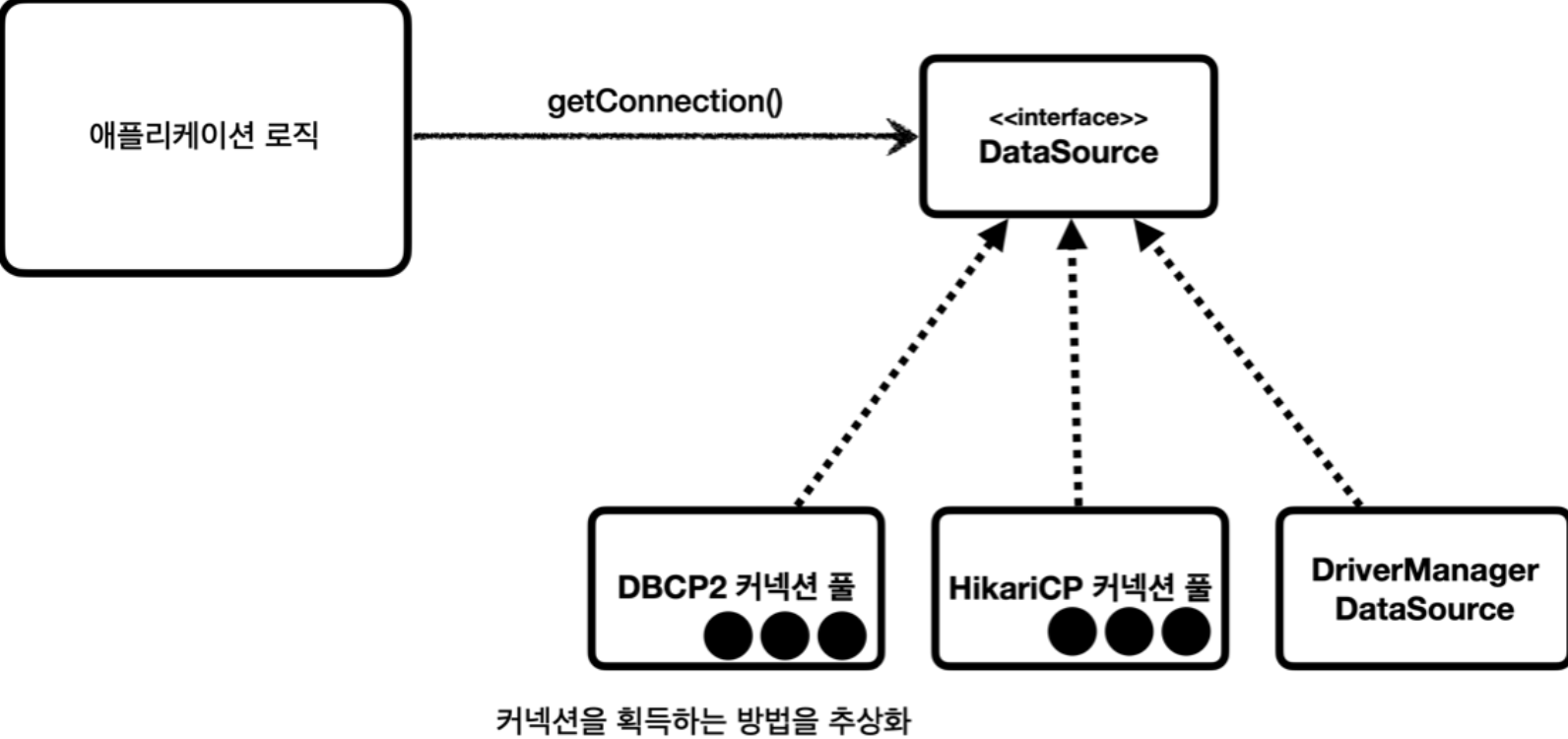
huisam 님의 블로그를 빌어 Datasource 는 아래와 같이 정리가 가능하기도 합니다.
- DB와의 연결을 위한 Factory의 역할로, Connection을 맺어주는 역할이다
- Connection 객체를 생성하면 관리는 Connection Manager에게 위임한다
- Transaction 관리자와 함께 활용되어 Transaction들을 처리한다
DataSource 를 통해 우리는 다양한 데이터베이스 커넥션 구현체를 호출하여 사용할 수 있다.
즉, DataSource 구현체를 구현하고 이를 활용하도록 해야 우리가 원하는 DB 에 접근할 수 있다.
DataSource 연결
DataSource 를 이용해서 2개 이상의 인스턴스를 연결하는 방법은 크게 2가지가 있다.
- RW / RO 별로 Datasource를 만들어 개발자가 선언하여 처리하는 방법
- Datasources에서 트랜잭션의 분기처리를 Lazy 하게 처리하는 방법
RW / RO 별로 Datasource를 만들어 개발자가 선언하여 처리
전체 소스 코드는 다음 링크에 있다.
간단하다고 생각할 수 있지만, 서로 다른 Datasource 를 가지는 도메인이 많으면 많을수록 복잡해진다.
application.yml
- spring.datasrource.master 로 master 데이터 소스 정보를 입력 받는다.
- spring.datasrource.slave 로 slave 데이터 소스 정보를 입력 받는다.
- jdbc-url 와 같은 네이밍은 DatasourceBuilder 를 이용하기 위함이다.
ReadWriteDatasourceConfiguration
- application.yml 로 부터 입력받은 프로퍼티 값을
DataSourceBuilder 를 통해서 입력받아 master/slave Datasource 를 반환한다. - @ConfigurationProperties 에 대해서 찾아보는 것도 추천한다.
UserDataSourceConfiguration.kt
- JPA 나 Jooq 와 같은 ORM 을 사용한다면 각각 필요한 빈들을 설정해주어야 한다.
- Read/Write 에 대한 EntityManagerFactory 를 만들어주어야하므로 별도 빈으로 생성했다.(RW/RO)
- Read/Write 에 대한 트랜잭션처리가 다르므로, 별도의 TransactionManager 들을 만들었다.(RW/RO)
- User 뿐만 아니라 Board 와 같은 각각의 도메인별 Datasource 마다 처리해주어야 한다.
UserUsecase
- Facade 서비스인 userUsecase 를 호출하여 각 비즈니스 로직을 처리하고 있다.
- 확실한 트랜잭션 분리를 위해 Read/Write 서비스를 분리하여 적용시켰다.
UserWriteService
- 서비스 레벨에서 Transactional 을 달아주었다.
- 여러 transactionManager 빈들이 올라가있으므로 명시적으로 사용할 빈을 지정한다.
- 여기서는 userReadWriteTransactionManger 이다.
UserReadService
- UserReadService 도 위와 같은 형태로 개발을 해놓았다.
해당 로직들을 기반으로 실행하면 아래와 같은 결과가 나타난다.
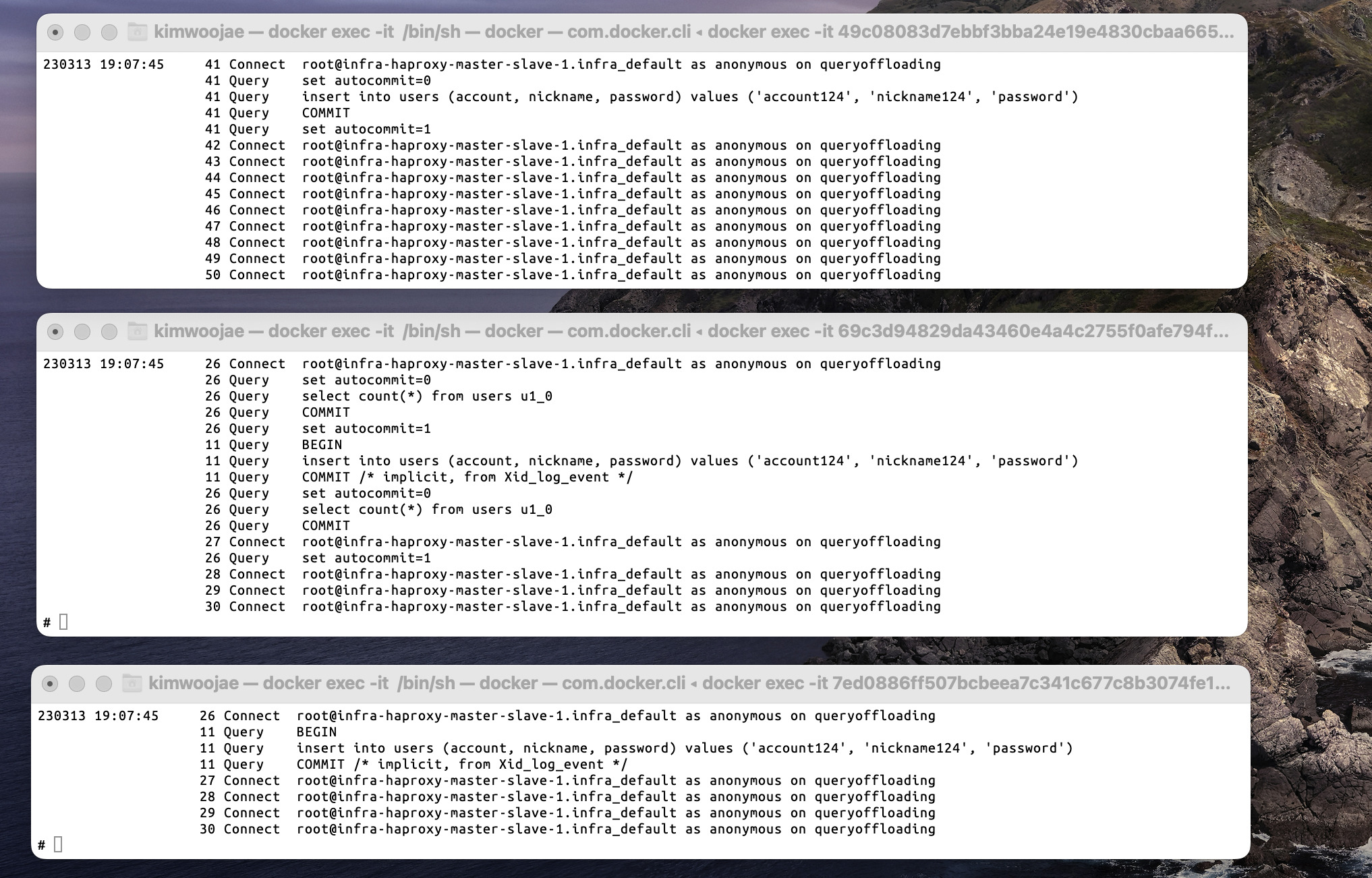
해석하자면 아래와 같다.
- Master-1-RW : Insert 구문이 동작한다.
- Slave-1-RO : Insert 구문(replication) + Select Count 구문
- Slave-2-RO : Insert 구문(replication)
단일 데이터 소스에서 트랜잭션의 분기처리를 Lazy 하게 처리
RoutingDataSource 처리 프로세스
스프링에서는 다양한 DataSource 맺고 이를 로직으로 Routing 처리할 수 있도록 지원하고 있다.
AbstractRoutingDataSource 추상 클래스를 구현하고 Bean으로 등록하면 자연스럽게 활용할 수 있다.
동작 방식은 아래와 같다.
- determineCurrentLookupKey()를 통해 LookupKey를 도출한다.
- LookupKey에 해당하는 dataSource가 Map에 있는지 확인하고 가져온다
- 존재하지 않는다면, resolvedDefaultDataSource()를 통해 defaultDataSource를 사용한다.
- defaultDataSource 조차도 없다면 IllegalStateException 예와가 발생한다
이제 동작 방식에 대해서 간단히 살펴보았으니 실제 구현을 진행해보자.
DataSourceRouter
RoutingDatasourceConfiguration
- Master 와 Slave 를 기준으로 Datasource 를 생성한다.
- 두 Datasource 를 기반으로, DataSourceRouter 를 정의하고 빈으로 등록한다.
- DataSourceRouter 를 내려받아 LazyConnectionDataSourceProxy 를 빈으로 등록한다.
LazyConnectionDataSourceProxy 는
실제 Connection 을 사용해야할 시점(트랜잭션 시점)에 Lazy 하게 조회해서 가져온다.
참고로 이렇게 빈 등록을 2개로 나눈 것은 AbstractRoutingDataSource 초기화 시점 때문이다.
AbstractRoutingDataSource 동작 방식
- AbstractRoutingDataSource 은 InitializingBean 을 구현하고 있다.
- afterPropertiesSet 을 살펴보면, targetDatasource 를 그제서야 resolvedDataSources 에 등록한다.
- 빈을 최초 생성하기 이전에, getConnection 을 호출하면 resolvedDataSources 가 아직 세팅되지 않았기에 에러가 발생한다.
LazyConnectionDataSourceProxy 동작 방식
- 정리하자면, LazyConnectionDataSourceProxy 은 생성자로 주입받은 Datasource 로부터 getConnection() 을 호출한다.
- 즉, 앞서 언급한대로 AbstractRoutingDataSource 의 생성 시점 이전이므로 에러가 발생한다.
- 참고로 최초 커넥션을 맺는 이유는, AutoCommit 과 Isolation 설정을 초기화하기 위해서다.
다시 본론으로 들어와서 위와 같은 환경 구성을 완료한다면
별도의 EntityManger 또는 TransactionManager 를 구성하지 않아도
@Transactional 의 readOnly 필드에 따라서 Datasource 를 달리 가져갈 수 있다.
참고
- https://huisam.tistory.com/entry/routingDataSource
- https://sightstudio.tistory.com/63
- https://github.com/woowacourse-teams/2021-gpu-is-mine/issues/399
[JPA] DataSource 를 연결하는 방법 & RoutingDataSource 설정
Java & kotlin 기반으로 Spring 을 개발하시는 분들은 너무나 익숙한 그림일텐데요 오늘은 Application과 JPA 단에 대해서 깊이 알아보는 시간보다는 DataSource를 통해서 어떻게 DataBase와 통신하는지에 대해
huisam.tistory.com
스프링에서 편리하게 Master / Slave 분기 처리하기
도입 실제 서비스를 운영하다 보면 데이터베이스가 여러 개의 노드로 분산되어 Master / Slave (또는 Multi Master) 구조로 이루어져 있는 경우가 많습니다. 이때 어플리케이션 레벨에서 어떻게 DataSource
sightstudio.tistory.com
DB Replication 설정하기 · Issue #399 · woowacourse-teams/2021-gpu-is-mine
이슈 설명 DB 가용성 증대와 단일 장애점 해소를 위한 Replication 도입
github.com