-
Redis 원정대 - 1 : NoSQL 과 RedisNoSQL 2023. 2. 28. 00:20
NoSQL 개요
2008년 아이폰 등장을 기점으로 실시간으로 다루어야 할 데이터가 폭발적으로 증가하기 시작했다.
이는 ‘데이터양의 증가’를 의미하게 되었고, 가변적인 데이터 처리를 요구하는 상황도 자주 발생했다.즉, 데이터 처리를 하는 서버 애플리케이션 개수를 동작 중에 늘리거나 줄이고
논리적으로 하나의 저장소이면서 언제든지 수평 확장 할 수 있는 새로운 패러다임이 필요해졌다.
(강력한 High Availability와 Horizontal Scalability를 지원하는 Database 요구)데이터 처리 요구 사항도 유기적으로 바뀌고 성능은 그대로 유지해야 한다는 점에서
관계형 데이터베이스의 Schema는 현대의 요구사항을 충족시켜 주기에는 부족한 점이 많았다.
(스키마 변경에 있어서 강한 제약 + 시간을 많이 사용해야 한다는 점이 있다.)이 같은 문제에 빗대어 Schemaless design, Dynamic Schema 이야기가 오르내리기 시작했고
잘 정규화된 데이터 구조보다는 필요에 따라 쉽게 변경할 수 있는 유연성이 더 필요해졌다.NoSQL 은 현대의 데이터 처리 요구사항을 만족하는 데이터베이스 패러다임이다.
NoSQL의 핵심 사항은 Horizontal Scalability과 High Availability으로
’DB 인스턴스’를 동적으로 손쉽게 추가할 수 있으며, 장애 발생에도 고 가용성을 제공하고자 한다.Horizontal Scalability과 High Availability
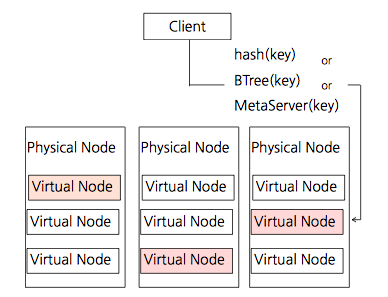
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=naverdev&logNo=120116323974 - Physical Node : 실제 서버 머신
- Virtual Node : NoSQL 서버 인스턴스
- 각각의 Disk Set 이 별도로 존재한다.
Hash , BTree , MetaSever를 통해 Key를 선정하고 특정 노드에 접근할 수 있다.
Key 생성 전략에 따라 선정할 수 있는 범위 내에 노드를 추가하거나 줄일 수 있다.- Replication을 두어, High Availability를 보장할 수 있다.
- 동적으로 Virtual Node를(또는 Physical Node를) 추가/삭제하고
자동으로 데이터가 복제/분산 된다면 Horizontal Scalability 도 보장할 수 있다.
당연하지만, 개발자가 어떤 전략을 가지고 가느냐에 따라 달라지므로 이를 유념하자.
추가로 NoSQL 과 RDB를 정리한 글도 첨부한다.NoSQL 어디에 쓰는가?, 이규재
많은 사람들이 관계를 맺고, 이 관계가 정보가 되는 소셜 서비스에서는 데이터를 효과적으로 다루기 위하여...
blog.naver.com
NoSQL 이 SQL 보다 빠르다?
NoSQL과 SQL에 대해서 일반적으로 생각한다면 자료 구조의 차이다.
데이터를 정규화하고 모델을 엄격히 관리하고 이들을 조합하는 것이 SQL이라면
데이터를 비 정규화하고 보다 유연한 모델링과 확장성을 가지는 것이 NoSQL이다.즉, 정규화된 데이터를 조합하는 모델링 구조라면 SQL 보다 NoSQL이 느리고
비 정규화된 데이터를 조회하는 모델링 구조라면 NoSQL 보다 SQL이 느리다.상황에 따라 다르겠지만 일반적으로 NoSQL이나 SQL이나 모두 비슷한 성능을 낼 수 있다.
다만, Relation DB의 경우 정렬, 부하를 해소하는 방법 등이 복잡한 단점이 있을 뿐이다.
따라서 NoSQL 이 SQL 보다 빠르다? 는 의미는 다소 견해가 있을 수 있다.Key-Value Database

Key라는 고유한 식별자를 가지고 어떤 Value 저장하는 형태의 데이터베이스를 의미한다.
단순한 자료구조로 인하여 데이터를 읽고 쓰는 것에 최적화가 되어있으며
주로 내부 설정 값 또는 캐싱의 용도로 사용되는 경우가 많다.- key는 NameSpace 별 고유한 값을 사용해야 한다.
- value는 간단한 데이터 타입부터 복잡한 객체일 수 있다.
- partitioning 이 가능하고 Scale-Out에 유리한 구조이다.(NoSQL)
대부분의 Key-Value Database는 데이터를 메모리에 적재하고 유지시간을 가지는 형태이다.
Relation DB의 경우, 데이터를 읽고 쓰는 데에 있어 Disk I/O 가 발생하는데
Key-Value Database는 이러한 비용이 비싼 Disk I/O를 최소화하기 위해 메모리를 사용한다.
(물론 절대적은 아니지만 대부분의 Key-Value Database 임을 가정하고 이야기한다.)Redis
Redis는 데이터베이스, 캐시, 메시지 브로커 및 스트리밍 엔진으로 사용되는 오픈소스로
기본적으로 Key-Value Database를 따르지만, 다양한 데이터 모델을(시계열, 스트림 등) 지원한다.Redis 사용 사례
Redis 는 Key-Value DataBase의 사용 사례처럼 사용 가능하지만,
Redis의 특징을 잘 살리고자 한다면, 실시간 조회 모델을 만드는 것에 초점을 맞출 수 있다.일반적인 Relation DB의 경우, 미리 정렬된 인덱스를 사용하지 않는 이상
재정렬을 위한 비용이 발생하며, 이는 곧 지속적인 Disk I/O가 발생을 의미한다.
특히, 실시간성 데이터의 경우 이 같은 현상은 더욱 심해지며,
결국 쓰기 요청에 대한 부하를 감당하지 못해 지연이 발생하고 장애로 이어질 수도 있다.Redis는 데이터를 저장할 때 가중치를 두어 미리 정렬된 데이터를 만들어 놓을 수 있다.(정렬 Sets)
실시간 데이터가 들어올 때마다 기존 데이터에 추가되고 정렬되며
이로 인한 쓰기 성능을 감소시키고, 읽기 성능을 향상한다고 볼 수 있다.일반적인 Application의 경우, 20% 의 쓰기와 80% 읽기로 이루어지기에
실시간성 조회 모델 의 경우 이 같은 방식이 알맞을 수 있다.Redis Architecture
Redis Architecture 는 버전마다 차이가 존재한다.
Redis Single Threading
기존 Redis 는 Single Thread 기반으로 동작을 했다.
Context Switching 이 없으며 읽기 성능도 110,000/s 정도로 매우 빨랐으며
쓰기 속도 또한 Single Thread 기반임에도 81,000/s로 빠른 속도를 자랑했다.하지만, Single Thread Model 로써 겪게 되는 문제들이 여럿 있는데 아래와 같다.
- 하나의 CPU Core 만을 사용할 수 있다.
- 삭제된 키가 너무 크면, 서버가 몇 초 동안 Blocking 된다.
- QPS(Queries Per Second)는 개선되기 어렵다.
특히, 대부분의 CPU 시간은 Network I/O 과정에서 시스템 호출을 실행하는 동안 점유된다.
이 같은 문제를 해결하기 위해, Redis 4.0과 Redis 6.0에서는
각각 Lazy Free와 Multi Thread I/O를 도입하여 점진적으로 Multi Thread 환경으로 전환하고 있었다.
Redis - 4.0 이전까지Redis 가 Single Thread 기반일 때 어떻게 동시 클라이언트 요청을 지원했을 끼?
이 질문을 답하기 위해 먼저 Redis 가 동작하는 원리에 대해서 알아가보자.- File Event
- Time Event
File Event.
- Redis Server는 Socket을 통해 클라이언트와 연결한다.
- File Event는 서버에서의 소켓 작업에 대한 추상화로 일컫어지는데
서버와 클라이언트 간의 통신은 File Event를 생성하고 서버는 File Event를 처리하여
일련의 네트워크 통신 작업(연결, 수락, 읽기, 쓰기)을 완료한다.
Time Event
- Redis 서버의 일부 작업은 지정된 시간에 실행되어야 하며
시간 이벤트는 만료된 키 정리 및 서비스 상태 만들기와 같은 종류의 타이밍 작업의 추상화다.
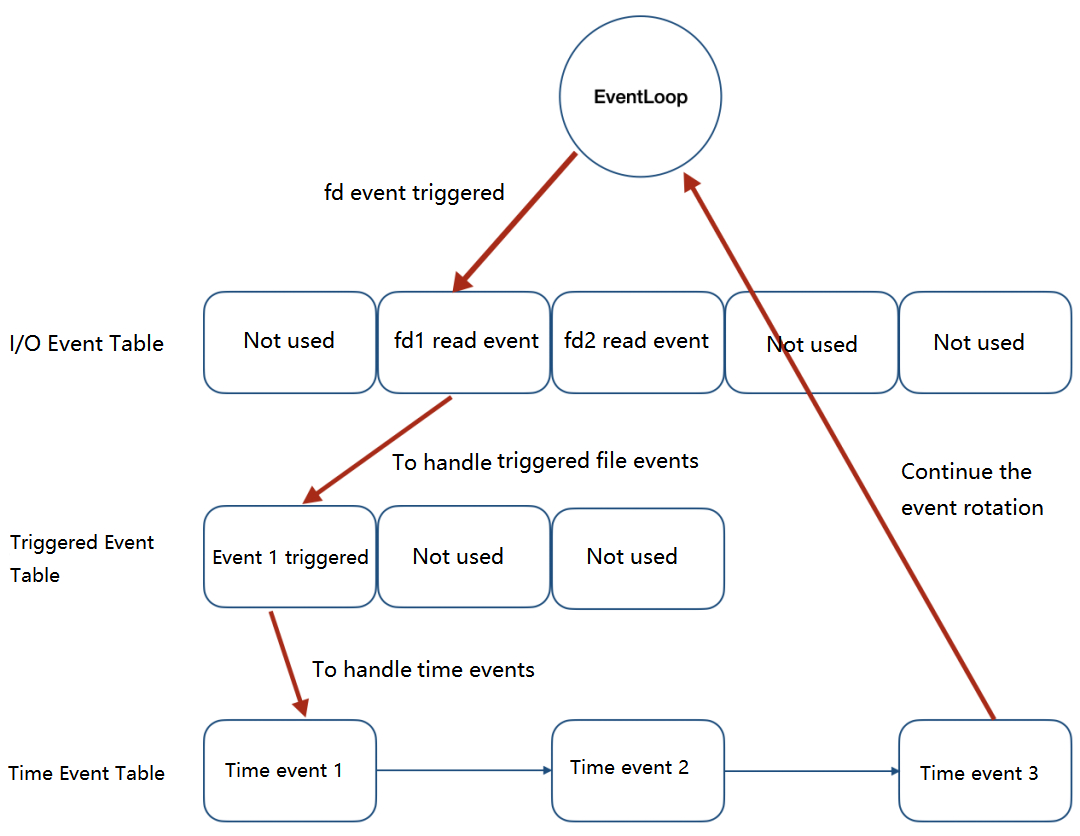
https://blog.squids.cn/why-does-redis-6.0-introduce-multithreading-what-are-the-advantages-of-using-multiple-processes.html
Redis는 File Event와 Time Event를 추상화한다.Time Selector는 I/O 이벤트 테이블을 모니터링하고 있다.
File Event 가 준비되면 Redis는 먼저 File Event를 처리한 다음 Time Event 를 처리한다.
위 모든 이벤트 처리를 Redis Single Thread 모델에서는 Single Thread로 처리한다.EventLoop(I/O Multi Flexing)
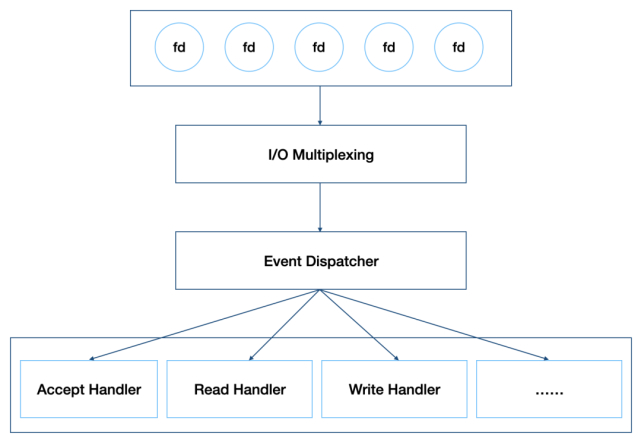
https://zhuanlan.zhihu.com/p/411057879 Redis는 Reactor 모델을 기반으로 자체 EventLoop(I/O Event Processor)를 개발했다.
Redis 는 I/O Event를 처리하기 위해 I/O Multiplexing 기술을 사용한다.동시에 어려 소켓을 모니터링하고 소켓을 다른 Event 처리 기능과 연결할 수 있다.
위와 같은 이유로, 하나의 스레드를 통해 여러 클라이언트의 동시 처리를 달성할 수 있었던 것이다.
이 디자인의 중요 요소로 데이터 처리에서 락을 필요로 하지 않으므로 간단하며 고성능을 보장한다.Redis Multi Threading
기존 Redis 는 단일 스레드 기반으로 요청을 4단계로 나누어 처리했다.
- reading the request from socket
- parsing it
- process it
- writing the response to socket
Redis 는 명령 실행 단계에서 서버에 도달하는 모든 명령이 즉시 실행되지 않았다.
모든 명령은 Socket Queue에 들어가고 Socket을 읽을 수 있게 되면
단일 Thread Event Dispatch 에 하나씩 전달되어 처리되는 형태를 가지고 있었다.여기에는 크게 2가지 문제가 존재한다.
- Socket Queue 에 요청이 들어와도 이미 다른 작업(4단계)을 처리하고 있다면 마무리 될 때까지 대기해야한다.
- 단순한 Key 전송만 하는 요청과 달리 크기가 큰 Value 에 대한 응답 쓰기는 느리므로 이에 대한 처리가 느릴 수 있다.
이 같은 문제점은 Redis 의 성능을 떨어뜨리게 만드는 병목 지점이며
이를 해결하기 위해서는 최소한의 영역들에 대해서 Multi Thread 방식 도입을 검토해야했다.Redis 4.0 - Sub-Thread
사실, Redis 의 Multi Threading 개념은 4.0 부터 도입된 것은 아니다.
버전 2.8에 처음으로 Sub-Thread 개념이 등장했으며, 3.2까지는 3개 쓰레드, 4.0부터는 4개 쓰레드가 동작한다.
출처 재발견시 링크 첨부 예정 - Main Thread
- Sub-Thread1(BIO-CLOSE-FILE Thread)
- Sub-Thread2(BIO-AOF-RESYNC Thread)
- Sub-Thread3(BIO-LAZY-FREE Thread)
기존 Redis 는 AE Event Model 과 I/O MultiFlexing 및 기타 기술을 통해
처리 성능이 높았기에 Multi Threading 방식에 대해서 비교적 회의적이였다.Single Thread 방식은 Redis 내부 구현의 복잡성을 크게 줄여주었는데
Hash 지연, Rehash, Lpush 및 기타 Thread Safe 하지 않은 명령에 대해서 Lock 없이 수행할 수 있도록 도와준다.그럼에도 불구하고, 몇몇 작업들에 대해서는 Single Thread 기반으로 동작하기에는 리스크가 많았다.
대표적인 예로, Redis의 persistence 를 지원하는 AOF 와 RDB 쓰기 작업은
Disk I/O 를 발생하기에 이에 대한 작업들은 Sub-Thread 를 두어 처리하도록 지원하고 있다.Redis 4.0 - Lazy Free Mechanism
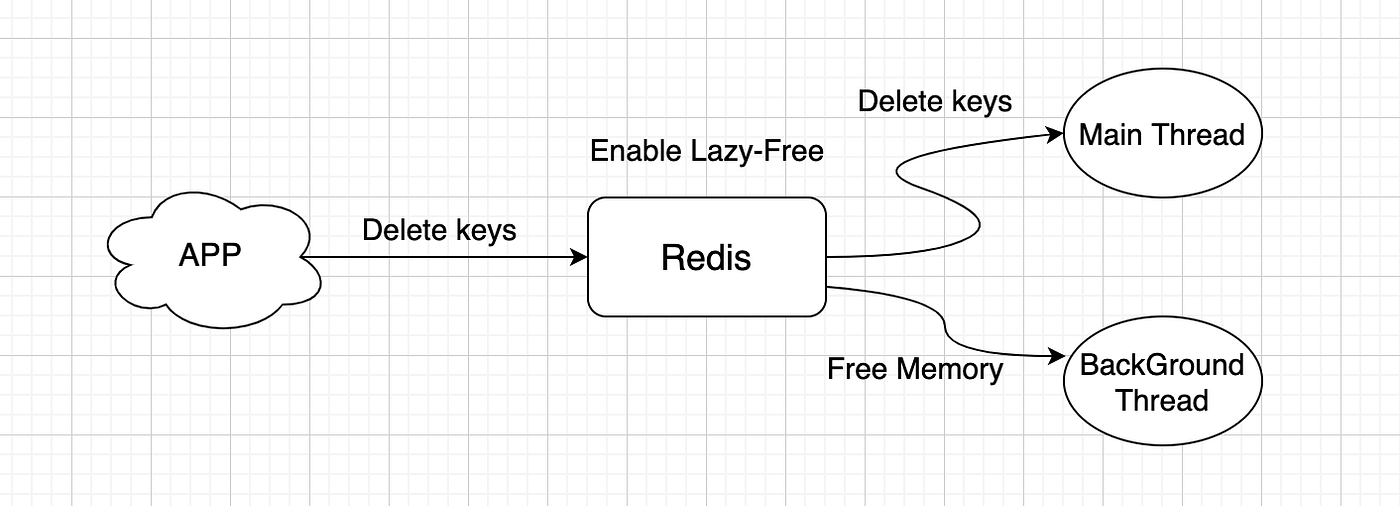
https://medium.com/sfu-cspmp/redis-the-optimal-solution-for-high-performance-data-retrieval-ecc2723d5cd4 Redis 에서 수백만 개의 객체가 포함된 Set 을 삭제하거나
flushdb 또는 flushall 과 같은 작업과 같이 수행하는데 많은 시간이 필요한 명령을 보내는 경우라면
Redis Server 는 많은 양의 메모리 공간을 회수해야 하므로 Block 이 발생하게 된다.이 같은 문제를 해결하기 위해서, Redis 버전 4.0 부터는 Lazy Free가 도입되었다.(정확히는 3.4)
Lazy Free 는 Redis 가 삭제할 키 중 규모가 큰 작업에 대해서는 비동기 멀티스레딩 처리를 하는 것이다.https://github.com/redis/redis/issues/1748
Lazy free of keys and databases · Issue #1748 · redis/redis
This issue is very long, so the gentle reader deserves a TL;DR: DEL and FLUSHALL / FLUSHDB are blocking commands, slow when called with large values / DBs. This issue proposes a way to free objects...
github.com
Lazy Redis is better Redis - <antirez>
antirez.com
백그라운드 삭제 요청을 단순하게 시간 이벤트 기반으로도 해결할 수도 있겠지만
메모리가 큰 수백만개의 개체를 소유한 Set 을 삭제한다고 가정한다면
제시간내에 삭제를 완료하지 못한 경우 데이터가 복구될 수 있고 메모리 고갈현상이 발생할 수 있다.따라서 Redis의 최종 구현은 메모리가 큰 키의 삭제를 비동기화하고 비차단 삭제를 채택하는 것이다.(UNLINK 명령어)
메모리가 큰 키의 공간 복구는 명령어를 처리하는 메인 스레드가 아닌 별도의 스레드에 의해 구현된다.
메인 스레드는 관계를 취소할 뿐이며, 신속하게 반환하고 다른 이벤트를 계속 처리하여 서버의 장기적인 차단을 방지한다./* Delete a key, value, and associated expiration entry if any, from the DB. * If there are enough allocations to free the value object may be put into * a lazy free list instead of being freed synchronously. The lazy free list * will be reclaimed in a different bio.c thread. */ #define LAZYFREE_THRESHOLD 64 int dbAsyncDelete(redisDb *db, robj *key) { /* Deleting an entry from the expires dict will not free the sds of * the key, because it is shared with the main dictionary. */ if (dictSize(db->expires) > 0) dictDelete(db->expires,key->ptr); /* If the value is composed of a few allocations, to free in a lazy way * is actually just slower... So under a certain limit we just free * the object synchronously. */ dictEntry *de = dictUnlink(db->dict,key->ptr); if (de) { robj *val = dictGetVal(de); // Calculate the recovery income of value size_t free_effort = lazyfreeGetFreeEffort(val); /* If releasing the object is too much work, do it in the background * by adding the object to the lazy free list. * Note that if the object is shared, to reclaim it now it is not * possible. This rarely happens, however sometimes the implementation * of parts of the Redis core may call incrRefCount() to protect * objects, and then call dbDelete(). In this case we'll fall * through and reach the dictFreeUnlinkedEntry() call, that will be * equivalent to just calling decrRefCount(). */ // Asynchronous deletion will be performed only when the recovery income exceeds a certain value, otherwise it will degenerate to synchronous deletion if (free_effort > LAZYFREE_THRESHOLD && val->refcount == 1) { atomicIncr(lazyfree_objects,1); bioCreateBackgroundJob(BIO_LAZY_FREE,val,NULL,NULL); dictSetVal(db->dict,de,NULL); } } /* Release the key-val pair, or just the key if we set the val * field to NULL in order to lazy free it later. */ if (de) { dictFreeUnlinkedEntry(db->dict,de); if (server.cluster_enabled) slotToKeyDel(key->ptr); return 1; } else { return 0; } }Redis 6.0 - Multi I/O Thread
시간이 지나면서, 하드웨어 성능 또한 월등히 향상되기 시작했고
단일 스레드 네트워크 읽기 및 쓰기 처리 속도가 기본 네트워크 하드웨어의 속도를 따라갈 수 없게 되었다.사실 Redis 의 병목 현상은 명령어를 처리하는데 문제가 있던 것이 아니라
주로, Network I/O 소비에서 비롯되었으며 해당 구간에 대해서 성능 개선이 필요했다.Redis 성능 병목 현상은 CPU가 아니라 메모리와 네트워크에 있다. Redis v6 부터, Redis 프로세스는 I/O 소켓에 읽고 쓰는 데 소요되는 시간을 I/O Thread 에 위임하여 데이터를 `조작`, `저장` 및 `검색`하는 데 더 많은 사이클을 할애하여 전반적인 성능을 향상시킨다.이 같은 문제에 생각해볼 수 있는 최적화 방법은 2가지였다.
- DPDK Network I/O 성능을 향상시키기 위해 커널 네트워크 스택을 교체하는 것
- 멀티 코어를 기반으로 하는 Multi Threading 방식을 통한 Network Read/Write 를 병렬 처리로 개선하는 것
1번의 경우, user mode network protocol stack 에 대한 지원을 추가해야하는데
이 방식은 Redis 소스 코드의 네트워크 관련 코어 부분을 수정해야 하기에 지원이 매우 어렵다.
여러 이유가 있겠지만, 새로운 코드 도입으로 인한 사이드 이펙트와 버그가 발생할 수 있기 때문이다.Redis 사에서 가장 중요로 목표하는 것중 하나는 기능에 대한 안정성과 하위 호환이다.
그렇기에 Redis 사에서는 Thread I/O 를 도입하여
Network Read/Write 요청을 병렬 처리로 개선하는 방식으로 개선했다.그리고 한가지 유의할 점은
Redis 다중 IO 스레드 모델은 네트워크 읽기 및 쓰기 요청을 처리하는 데만 사용되며
Redis 읽기 및 쓰기 명령의 경우 여전히 단일 스레드에서 처리된다.Redis v6 프로세스
- Main Thread 는 Connection 요청을 수신하고 Socket Queue 에 Socket을 배치한다.
- 풀링을 통해서 Socket Queue 에 저장된 Socket 들을 I/O Thread 가 처리하는 영역으로 옮긴다.
- Main Thread 는 I/O Thread 가 Socket 작업을 완료할 때 까지 기다린다.
- I/O Thread 의 작업이 끝나면 Main Thread 는 실제 Redis 요청 명령을 실행한다.
- Main Thread의 작업이 끝나면 I/O Thread 가 명령에 대한 결과를 쓰기 시작하며
Main Thread 는 I/O Thread 가 쓰기 작업을 완료할 때 까지 기다린다. - Main Thread 는 클라이언트의 후속 요청을 처리하거나 기다린다.
반복적으로 언급하지만 여기서 핵심은,
메인 스레드 IO 읽기 및 쓰기 작업을 독립 스레드 그룹으로 처리하여
여러 소켓 읽기 및 쓰기를 병렬화 할 수 있지만
Redis 명령은 여전히 메인 스레드에서 직렬로 실행된다.Multi Threading 활성 방법
- 기본적으로 비 활성화되어 있으며 Main Thread 만 사용된다.
- 활성화하려면 redis.conf 파일을 io-threads-do-reads yes 로 수정해야 한다.
적절한 Thread 수 설정
- 4코어는 2또는 3개로 Thread 로 설정
- 8코어는 6개의 Thraed 로 설정
- Thread 수는 CPU 코어 수보다 작아야 한다.
- 관계자들은 8 이상은 기본적으로 의미가 없다고 생각한다.
- 또한 멀티 스레딩을 활성화한 후에는 스레드 수를 설정하지 않으면 적용되지 않는다.
'NoSQL' 카테고리의 다른 글
MongoDB Persistence (0) 2023.04.06 Redis 원정대 - 4 : Redis Pub/Sub (0) 2023.03.03 Redis 원정대 - 3 : Redis Pipelining (0) 2023.03.02 Redis 원정대 - 2 : Redis Client-Cache (0) 2023.03.02