-
Reactive 여정기(1부) - I/O Multiplexing 과 Asynchronous I/O 그리고 Event LoopSpring 2023. 7. 26. 23:58
1. I/O Multiplexing
1.1. 개요
I/O Multiplexing 이란 단어는 어디서 한 번쯤 들어보았지만
실제 어떤 기술인지 그리고 어디서, 어떻게 활용 되는지에 대해서 모르는 경우가 많습니다.
그래서 이번 포스팅에서는 비전공자 관점으로 최대한 쉽게 풀어서 설명을 해보려 합니다.
우선, 포스팅 할 내용과 관련해서 시리즈로 작성하려 하는데 전체적인 구상은 아래와 같습니다.- I/O Multiplexing
- JVM 환경에서의 I/O Multiplexing 구현 기술
- Spring과 I/O Multiplexing 구현 기술
- Netty와 Armeria 구현 기술
1.2. 어디서 사용되는가?어떤 지식을 학습하고 체득하기 위해서는 나무가 아니라 숲을 볼 줄 알아야 하는 것이라 생각합니다.
단순히 개념점, 문법적 지식만을 나열하고 설명하는 것이 아니라
우리가 배우고자 하는 것은 무엇인지 그리고 어디서 사용되는지 간단히 말하고자 합니다.우선 처음 I/O Multiplexing 단어를 알게 된 것은 다름이 아닌 Redis입니다.
Redis의 구현 기술을 살펴보면 처음 등장부터 Asynchronous I/O 를 지원하도록 설계되었습니다.
Redis는 클라이언트 요청을 비동기적으로 읽어 들이고 응답을 비동기적으로 전송합니다.
흔히들 Redis 를 Single Thread라고 이해하는 경우가 많은데 반은 맞고 반은 틀립니다.
Redis는 요청/응답 과정에서 최대한 퍼포먼스를 높이기 위해 Multi Thread 방식으로 동작합니다.이 외에도 I/O Multiplexing 은 다양한 곳에 사용되는데 대표적으로 Spring WebFlux 가 있습니다.
Spring WebFlux는 Reactor 라이브러리를 기반으로 구현되어, 리액티브 프로그래밍 모델을 제공합니다.
이를 통해 I/O Multiplexing과 Event Loop를 사용하여 논블로킹 방식으로 웹 요청을 처리합니다.- WebClient :
- Spring WebFlux 에서 제공하는 비동기 HTTP 클라이언트 라이브러리입니다.
- Non-Blocking 방식으로 외부 API 호출 등의 비동기적인 웹 요청을 처리할 수 있습니다.
- Controller와 RouterFunction:
- Spring WebFlux에서는 함수형 엔드포인트를 정의하는 RouterFunction을 제공합니다.
- 더 유연한 논블로킹 방식으로 엔드포인트를 정의할 수 있습니다.
- WebFlux Runtime :
- Spring WebFlux는 Netty 또는 Undertow와 같은 Runtime을 기반으로 작동합니다.
- I/O Multiplexing과 Event Loop를 활용하여 Non-Blocking 웹 서버를 제공합니다.
이렇듯 I/O Multiplexing 과 파생 개념들은 우리 개발 환경에 밀접하게 존재하고 있습니다.
그렇기에 우리는 해당 개념에 대해서 알아야 하며 이를 잘 다룰 수 있어야 한다고 생각합니다.1.3. I/O 와 Thread 의 관계

파일 시스템을 다루는 Single Thread 환경이라고 가정을 합니다.
일반적으로 File I/O 와 같은 I/O 작업들은 Kernel Mode를 사용합니다.
그리고 Kernel Mode 에서 파일에 대한 작업을 모두 처리할 때까지 Sync-Blocking 됩니다.
스레드가 처리할 수 있는 처리량 보다 많은 I/O 작업이 들어오게 된다면? 그런데 만약 위와 같이 Thread 의 처리량보다 처리해야 할 파일의 수가 많으면 어떻게 될까요?
첫 번째 파일은 Thread에 의해서 처리가 되겠지만, 나머지 파일들은 대기가 되는 현상이 발생됩니다.
즉, 작업들이 처리가 되지 않고 대기가 되면서 전체 처리량을 감소시키는 악영향을 일으킵니다.

멀티 프로세스 or 멀티 스레드 이 같은 문제를 해결하기 위해서 아래 2가지 방식을 고려해 볼 수 있을 것 같습니다.
- 멀티 스레드를 이용한 처리
- 멀티 프로세스를 이용한 처리
두 방법 모두 현재 주어진 문제를 해결하는데 문제는 없어 보입니다.
하지만, Multi Process 의 경우 Context Switching 비용이 매우 비싸다는 단점이 있으며
Multi Thread 의 경우에도 처리에 한계가 있으며, 여전히 모든 Thread 가 Blocking 당하기 쉽습니다.그렇다면 근본적인 문제를 한번 생각해 봅시다.
Kernel Mode 진입과 동시에 Thread 가 대기 상태가 되어 다른 작업들을 처리할 수 없는 게 문제입니다.
그렇다면 I/O 작업은 따로 CPU 작업은 따로 동작할 수 있게 된다면 이 문제가 해결되지 않을까요?1.4. I/O Multiplexing의 등장

이러한 고민에서 출발하여 탄생한 개념이 바로 I/O Multiplexing입니다.
주로 비동기적인 I/O 처리를 위해 사용하는 경우가 많고,
Single Thread 환경에서 여러 개의 I/O 작업을 효율적으로 처리할 수 있도록 도와줍니다.결과적으로 Multi Thread 보다 훨씬 적은 리소스를 사용하면서 더 높은 처리량과 성능을 제공합니다.
이를 통해 대규모 동시 접속을 처리하는 서버나 입출력 집약적인 애플리케이션에서 효과적으로 활용됩니다.사실, I/O Multiplexing는 Asynchronous I/O 와 Event Loop의 결합이라고 볼 수 있습니다.
그렇다면 각각의 기술들이 어떤 것이며 어떻게 활용되는지 한 번 알아봅시다.
2. Asynchronous I/O
Asynchronous I/O 는 비동기적으로 I/O 작업을 수행하는 방식을 말합니다.
I/O 작업이 완료될 때까지 blocking 되지 않고 다른 작업을 수행할 수 있도록 도와줍니다.
I/O 작업이 완료되면 애플리케이션에 알림을 전달하여 결과를 처리할 수 있게 합니다.2.1. 알고 보면 좋을 CS 개념
Linux와 Windows와 같은 OS 들은, 파일과 같은 리소스를 관리하기 위한 개체를 만듭니다.
- Windows : KernelObject - Handle - KernelObjectTable
- Linux : FileDescriptor - FileDescriptorTable
리소스를 관리하는 테이블들이 존재하면 이들은 프로세스가 초기화될 때 생성됩니다.
OS는 해당 테이블의 정보를 통해 파일, 소켓과 같은 리소스들을 관리합니다.2.1.1. Windows Kernel Object

windows에서는 리소스들을 관리하기 위해 Kernel Object와 Handle이라는 개념이 있습니다.
Kernel Object는 Kernel 에 의해 관리되는 리소스 정보를 담고 있는 데이터 블록(파일)을 말합니다.
Kernel Object 는 매우 중요한 요소이기 때문에 OS에 의해 관리됩니다.
그렇기에 별도의 Handle(간접 접근)을 제공하여 Kernel Object에 대한 제한된 접근을 지원합니다.일반적으로 프로세스가 관리해야 하는 리소스는 한 개가 아닙니다.
이들을 관리하기 위해 프로세스 초기화될 때 Kernel Object Handle Table을 만듭니다.2.1.2. Linux File Descriptor

Linux에서는 File과 Socket 등의 리소스를 관리하기 위해서 File Descriptor 개념이 있습니다.
File Descriptor와 File Descriptor Table을 통해 각 파일들의 접근을 관리합니다.
그래서 리눅스에서는 모든 것이 File이다.라는 말도 전해지고 있습니다.2.2. 그래서 Asynchronous I/O 란 무엇인가?

Linux의 전통적인 I/O 모델은 File Descriptor를 이용한 Sync-Blocking I/O였습니다.
즉, 사용자는 하나의 전달(Transfer)을 하고 System Call로 이에 대한 응답을 하는 구조였습니다.Linux 2.5~2.6부터는 Asynchronous I/O 가 도입되어 복수의 전달(Transfer)이 가능해졌습니다.
복수의 전달(Transfer) 이기 때문에 각 전달(Transfer) 들을 식별하기 위한 식별자도 필요했지만
이를 AIOCB(Async I/O Control Block) 구조체로 구현하여 잘 사용하고 있습니다.
참고로, AIOCB는 전달(Transfer)에 관한 정보를 담고 있고, 데이터에 관한 사용자 버퍼도 포함하고 있습니다.정리하자면, 한 I/O 에서 작업이 완료되면 전달(Transfer)들에 대한 알림이 발생됩니다.
이를 Completion이라 부르며 각 전달(Transfer)들을 식별하기 위해 AIOCB를 활용합니다.2.3. Asynchronous I/O 와 File Descriptor
Linux의 Asynchronous I/O 는 posix의 AIO API를 기반으로 구현되었습니다.
Asynchronous I/O 는 앞서 언급한 File Descriptor를 기반으로 동작이 가능하며
아래 3개의 System Call 은 Asynchronous I/O 를 구현한 메서드입니다.2.3.1. Select

Select는 여러 개의 파일을 다루기 위해서, File Descriptor를 배열(그룹)로 관리합니다.
데이터 변경(작업 수행 여부)을 감시할 File Descriptor를 배열에 포함시키고
읽기, 쓰기, 에러와 같은 데이터 변경이 발생하면 대응되는 배열에 표시를 하는 방식입니다.
즉, 개발자는 File Descriptor 배열의 값을 검사하는 것으로 여러 파일들을 처리할 수 있습니다.
이 같은 File Descriptor로 이루어진 배열을 우리는 fd_set이라고 부릅니다.
fd_set 은 비트 배열로서 총 1024개의 파일을 감시할 수 있습니다.File Descriptor를 감시하는 것은 알겠지만, 이들을 동시에 관리하기는 어렵습니다.
만약 파일을 1024개 관리하고 1023번 File Descriptor에 Read 플래스가 1이 되었다면
모든 fd_set을 검사해야만 하고 이를 통해 변화가 있는 File Descriptor를 알 수 있습니다.이처럼 Select는 쉬운 구현으로 다양한 OS에서 지원을 하며 파일을 다중으로 처리하기 좋으나
매번 O(N)의 모니터링을 위한 반복이 필요하고 배열의 개수가 1024로 제한되는 문제가 있습니다.장점 • 단일 프로세스(스레드)에서 여러 입출력 처리가 가능한 덕분에 동시에 수만 개의 커넥션도 처리할 수 있다.
이를 바탕으로 C10k problem을 해결할 수 있다.
• POSIX 표준을 따르기 때문에 지원하는 운영 체제가 많아 이식성이 좋다.
• 클라이언트 요청마다 처리하기 위한 별도 스레드를 만들지 않기 때문에
컨텍스트 전환(context switching) 오버헤드가 발생하지 않는다.단점 • select 함수를 호출해서 전달된 정보는 커널에 등록되지 않은 것이기 때문에
select 함수를 호출할 때마다 매번 관련 정보를 전달해야 한다.
• select 함수의 호출 결과가 이벤트가 발생한 파일 디스크립터의 개수이기 때문에
어떤 파일 디스크립터에서 이벤트가 발생했는지 확인하기 위해서는 매번 fd_set 테이블 전체를 검사해야 한다.
• 검사할 수 있는 파일 디스크립터 개수에 제한이 있다(최대 1024개).
• select 함수를 호출할 때마다 데이터를 복사해야 한다.
(select 함수를 호출한 후 이벤트를 처리할 때 fd_set 테이블 변경이 필요하기 때문에 미리 복사가 필요하다)2.3.2. Poll
Poll 은 Select와 유사하게 동작을 하지만, File Descriptor에 대한 제한이 없는 게 특징입니다.
여러 File Descriptor를 모니터링하다가 File Descriptor 중 하나에 입출력 가능한 이벤트가 발생하면
해당 파일 디스크립터를 반환하고 프로그램은 이벤트를 처리하게 됩니다.(Blocking 해제)장점 • select 와 같이 단일 프로세스(스레드)에서 여러 파일의 입출력 처리가 가능하다.
• select 방식처럼 표준 입력, 출력, 에러를 따로 감시할 필요가 없다.
• select 는 timeval 이라는 구조체를 사용해 타임아웃 값을 설정하지만,
poll 은 별다른 구조체 없이 타임아웃을 설정할 수 있다.단점 • 일부 UNIX 시스템은 poll을 지원하지 않는다. 2.3.3. Epoll

Linux 커널 2.5.44에 도입된 System Call 로서,
File Descriptor 수에 제한이 없으며 상태 변화 모니터링을 커널에 위임시킨 것이 특징입니다.
즉, 커널에 관찰 대상에 대한 정보를 한 번만 전달하고 관찰 대상의 범위나 내용에 변경이 있을 때만 변경 사항을 알림 받을 수 있습니다.events에 들어있는 데이터는 모두 읽을 수 있는 File Descriptor 덕분에 O(1)의 계산량으로 끝납니다.
Select, Poll처럼 모니터링을 위한 루프가 불필요해졌으며 효율적인 I/O를 구현하게 해 줍니다.정리하자면, Select와 Poll 은 상태가 변화된 File Descriptor의 개수만을 반환했기에
실제로 어떤 File Descriptor 가 변화되었는지 확인하려면 O(N)의 반복문이 필요했습니다.
하지만, Epoll 은 이 작업들이 Kernel로 넘어갔으며,
개수가 아닌 실제 목록을 반환하기에 추가적인 반복문이 불필요하고 전달받은 목록만을 가지고 작업을 수행하면 됩니다.장점 • 상태 변화를 확인하기 위한 전체 파일 디스크립터 대상 반복문이 필요 없다.
• select 함수에 대응하는 epoll_wait 함수를 호출할 때 커널에서 상태 정보를 유지하기 때문에
관찰 대상의 정보(fd_set)를 매번 전달할 필요가 없다.단점 • Linux의 select 기반 서버를 Window의 select 기반 서버로 변경하는 것은 비교적 간단하나,
Linux의 epoll 기반의 서버를 Windows의 IOCP 기반으로 변경하는 것은 select를 이용하는 것보다 번거롭다.
3. Event Loop
Event Loop는 이벤트 기반 메커니즘을 사용하여, 비동기적으로 작업을 처리하는 방식을 말합니다.
주로 이벤트 큐를 감시하고, 이벤트가 발생하면 해당 이벤트를 처리합니다.
이러한 방식으로 여러 작업을 비동기적으로 처리하고, Blocking 없이 이벤트를 처리할 수 있습니다.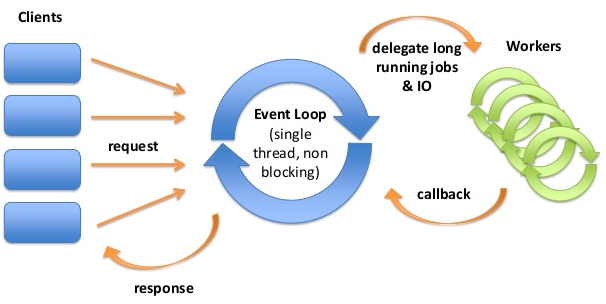
Asynchronous I/O 의 System Call을 사용했다면, 처리 결과인 Event 목록을 Event Queue에 담습니다.
그리고 Event Loop의 Single Thread는 Event Queue를 감시하며 적재된 Event를 하나씩 꺼내어
Event에 대한 CallBack 처리를 Workers에 위임합니다.
이때 가장 중요한 점은 Event Loop를 구현한 스레드가 Blocking 되지 않도록 설계해야 합니다.
3.1. Event Loop 스레드를 Block 하면 발생하는 문제해당 섹션은 Armeria를 기반으로
비동기 서버에서 이벤트 루프를 블록 하면 안 되는 이유 1부 게시글 내용을 참조해서 작성했음을 미리 언급하고 가겠습니다.
Armeria는 요청이나 응답에 공통 로직을 추가할 수 있는 decorator를 제공하고 있습니다.만약 authenticate()에서 Blocking 이 발생하면 어떤 문제가 발생할까요?
몇 건의 요청 처리 후 API 응답 속도가 느려지거나 응답 불능 상태가 될 수 있습니다.이유는 Event Loop 스레드가 Blocking I/O 로직을 호출하게 되면서 Blocking 상태가 되고
이로 인해 Event Queue의 작업들은 처리되지 못하고 지속적으로 쌓이게 되며
결국 다른 요청들을 처리할 수 없거나 밀리게 되는 문제가 발생하게 됩니다.
즉, Event Queue로부터 Event를 읽어서 동작하는 Thread 가 Block 되어 문제가 발생한 것입니다.이 같은 문제를 해결하기 위해서는 스레드의 역할과 책임을 잘 나누어야 합니다.
Event Loop Thread는 Event를 꺼내어 Workers에 위임하는 Non-Blocking 하도록 설계해야 하고
Worker Thread 들은 Event에 대한 콜백 처리를 할 수 있도록 설계하는 것이 좋습니다.
(Blocking 이 발생해도 Workers 중 일부 Thread 만 Blocking 상태가 되는 것이므로)
4. 참조한 내용
- https://notes.shichao.io/unp/ch6/
- https://plummmm.tistory.com/68
- https://blog.naver.com/n_cloudplatform/222189669084
- https://www.youtube.com/watch?v=mb-QHxVfmcs&ab_channel=쉬운 코드
- https://engineering.linecorp.com/ko/blog/do-not-block-the-event-loop-part1
- https://engineering.linecorp.com/ko/blog/do-not-block-the-event-loop-part2
- https://engineering.linecorp.com/ko/blog/do-not-block-the-event-loop-part3
- https://www.getoutsidedoor.com/2021/10/03/eventloop-설계와-구현-el-project
- https://www.baeldung.com/spring-webflux-concurrency
'Spring' 카테고리의 다른 글
Reactive Streams 여정기(2부) - JVM 과I/O (0) 2023.08.06 FCM과 함께 춤을(발행 보장) (0) 2023.07.16 FCM 과 함께 춤을(튜닝) (0) 2023.06.03 Spring 에서 Master Slave Datasource 분리하기 (1) 2023.03.14